Append a new batch of data#
We have one file in storage and are about to receive a new batch of data.
In this notebook, we’ll see how to manage the situation.
import lamindb as ln
import lnschema_bionty as lb
import readfcs
lb.settings.species = "human"
💡 loaded instance: testuser1/test-facs (lamindb 0.54.4)
ln.track()
💡 notebook imports: anndata==0.9.2 lamindb==0.54.4 lnschema_bionty==0.31.2 pytometry==0.1.4 readfcs==1.1.6 scanpy==1.9.5
💡 Transform(id='SmQmhrhigFPLz8', name='Append a new batch of data', short_name='facs1', version='0', type=notebook, updated_at=2023-10-02 10:21:18, created_by_id='DzTjkKse')
💡 Run(id='MAsFiWynt6ZzShK6Xhp5', run_at=2023-10-02 10:21:18, transform_id='SmQmhrhigFPLz8', created_by_id='DzTjkKse')
Ingest a new file#
Access  #
#
Let us validate and register another .fcs file:
filepath = ln.dev.datasets.file_fcs()
adata = readfcs.read(filepath)
adata
AnnData object with n_obs × n_vars = 65016 × 16
var: 'n', 'channel', 'marker', '$PnB', '$PnR', '$PnG'
uns: 'meta'
Transform: normalize  #
#
import anndata as ad
import pytometry as pm
pm.pp.split_signal(adata, var_key="channel")
pm.tl.normalize_biExp(adata)
adata = adata[ # subset to rows that do not have nan values
adata.to_df().isna().sum(axis=1) == 0
]
adata.to_df().describe()
| KI67 | CD3 | CD28 | CD45RO | CD8 | CD4 | CD57 | CD14 | CCR5 | CD19 | CD27 | CCR7 | CD127 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 64593.000000 | 64593.000000 | 64593.000000 | 64593.000000 | 64593.000000 | 64593.000000 | 64593.000000 | 64593.000000 | 64593.000000 | 64593.000000 | 64593.000000 | 64593.000000 | 64593.000000 |
| mean | 995.527609 | 991.177964 | 987.078176 | 992.669879 | 997.885007 | 991.256722 | 992.786610 | 991.668695 | 1005.040547 | 990.848286 | 992.297503 | 1000.381267 | 1004.603404 |
| std | 1250.888451 | 1247.088234 | 1243.992707 | 1247.520841 | 1251.943558 | 1247.162966 | 1249.840684 | 1244.215164 | 1258.626730 | 1247.542888 | 1246.295504 | 1251.073884 | 1254.980319 |
| min | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 457.194312 | 457.194312 | 457.194312 | 457.194312 | 457.194312 | 457.194312 | 457.194312 | 457.194312 | 457.194312 | 457.194312 | 457.194312 | 457.194312 | 457.194312 |
| 50% | 462.811405 | 462.810928 | 462.810928 | 462.810928 | 462.811394 | 462.810928 | 462.811362 | 462.810928 | 462.811424 | 462.810928 | 462.810928 | 462.811400 | 462.811491 |
| 75% | 1087.252514 | 1064.944577 | 939.866561 | 1067.880110 | 1096.877718 | 1033.079126 | 1037.662928 | 1063.171051 | 1119.130893 | 1002.628162 | 1092.763905 | 1121.682920 | 1174.015294 |
| max | 4096.000000 | 4096.000000 | 4096.000000 | 4096.000000 | 4096.000000 | 4096.000000 | 4096.000000 | 4096.000000 | 4096.000000 | 4096.000000 | 4096.000000 | 4096.000000 | 4096.000000 |
Validate cell markers  #
#
Let’s see how many markers validate:
validated = lb.CellMarker.validate(adata.var.index)
❗ 7 terms (53.80%) are not validated for name: KI67, CD45RO, CD4, CD14, CCR5, CD19, CCR7
Let’s standardize and re-validate:
adata.var.index = lb.CellMarker.standardize(adata.var.index)
validated = lb.CellMarker.validate(adata.var.index)
❗ found 1 synonym in Bionty: ['KI67']
please add corresponding CellMarker records via `.from_values(['Ki67'])`
❗ 3 terms (23.10%) are not validated for name: Ki67, CD45RO, CCR5
Next, register non-validated markers from Bionty:
records = lb.CellMarker.from_values(adata.var.index[~validated])
ln.save(records)
Now they pass validation:
validated = lb.CellMarker.validate(adata.var.index)
assert all(validated)
Register  #
#
modalities = ln.Modality.lookup()
features = ln.Feature.lookup()
efs = lb.ExperimentalFactor.lookup()
species = lb.Species.lookup()
markers = lb.CellMarker.lookup()
file = ln.File.from_anndata(
adata,
description="Flow cytometry file 2",
field=lb.CellMarker.name,
modality=modalities.protein,
)
/opt/hostedtoolcache/Python/3.9.18/x64/lib/python3.9/site-packages/anndata/_core/anndata.py:1230: ImplicitModificationWarning: Trying to modify attribute `.var` of view, initializing view as actual.
df[key] = c
... storing '$PnR' as categorical
/opt/hostedtoolcache/Python/3.9.18/x64/lib/python3.9/site-packages/anndata/_core/anndata.py:1230: ImplicitModificationWarning: Trying to modify attribute `.var` of view, initializing view as actual.
df[key] = c
... storing '$PnG' as categorical
❗ 3 terms (100.00%) are not validated for name: FSC-A, FSC-H, SSC-A
❗ no validated features, skip creating feature set
file.save()
file.labels.add(efs.fluorescence_activated_cell_sorting, features.assay)
file.labels.add(species.human, features.species)
file.features
Features:
var: FeatureSet(id='7J3Su8wy2U2PnMiLgeGq', n=13, type='number', registry='bionty.CellMarker', hash='cInZdHy3fspNNLGysq01', updated_at=2023-10-02 10:21:21, modality_id='EFBdjpXy', created_by_id='DzTjkKse')
'CD3', 'Ccr7', 'CD28', 'CD45RO', 'Cd14', 'Cd4', 'Cd19', 'CD57', 'CD127', 'Ki67', 'CCR5', 'CD27', 'CD8'
external: FeatureSet(id='W8W3sdej2JMu852vJAcA', n=2, registry='core.Feature', hash='ImQPRYuWxRjMVJdunJJg', updated_at=2023-10-02 10:21:21, modality_id='shAk3Do6', created_by_id='DzTjkKse')
🔗 assay (1, bionty.ExperimentalFactor): 'fluorescence-activated cell sorting'
🔗 species (1, bionty.Species): 'human'
View data flow:
file.view_flow()

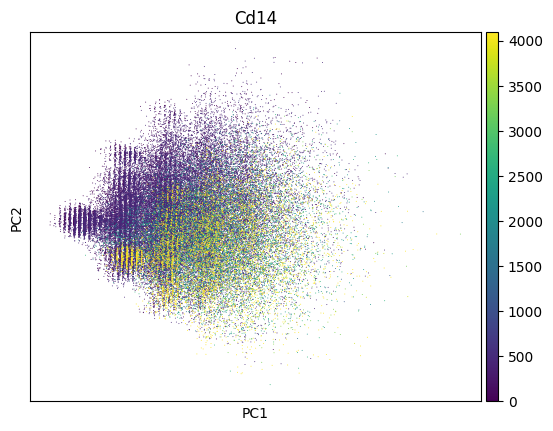
Inspect a PCA fo QC - this dataset looks much like noise:
import scanpy as sc
sc.pp.pca(adata)
sc.pl.pca(adata, color=markers.cd14.name)
Create a new version of the dataset by appending a file#
Query the old version:
dataset_v1 = ln.Dataset.filter(name="My versioned cytometry dataset").one()
dataset_v2 = ln.Dataset(
[file, dataset_v1.file], is_new_version_of=dataset_v1, version="2"
)
dataset_v2
Dataset(id='UYxBk5c2glqsNytkYhPu', name='My versioned cytometry dataset', version='2', hash='cSKkfcii0eGS8TGGTW53', transform_id='SmQmhrhigFPLz8', run_id='MAsFiWynt6ZzShK6Xhp5', initial_version_id='UYxBk5c2glqsNytkYhWE', created_by_id='DzTjkKse')
dataset_v2.features
Features:
var: FeatureSet(id='vfekByORnfOKR2m3c12C', n=48, type='number', registry='bionty.CellMarker', hash='lta50RjC3dMs1x5JqZxy', created_by_id='DzTjkKse')
'CD3', 'Ccr7', 'CD28', 'CD45RO', 'Cd14', 'Cd4', 'Cd19', 'CD57', 'CD127', 'Ki67', 'CCR5', 'CD27', 'CD8', 'Ccr7', 'CD27', 'CD33', 'CD3', 'CD16', 'CXCR3', 'CD38', ...
obs: FeatureSet(id='D9IelF210m2KvoLE4tz2', n=5, registry='core.Feature', hash='kN_l0cF14_oL_mMi1lHi', updated_at=2023-10-02 10:21:10, modality_id='shAk3Do6', created_by_id='DzTjkKse')
Time (number)
Dead (number)
Bead (number)
Cell_length (number)
(Ba138)Dd (number)
external: FeatureSet(id='W8W3sdej2JMu852vJAcA', n=2, registry='core.Feature', hash='ImQPRYuWxRjMVJdunJJg', updated_at=2023-10-02 10:21:21, modality_id='shAk3Do6', created_by_id='DzTjkKse')
🔗 assay (0, bionty.ExperimentalFactor):
🔗 species (0, bionty.Species):
dataset_v2
Dataset(id='UYxBk5c2glqsNytkYhPu', name='My versioned cytometry dataset', version='2', hash='cSKkfcii0eGS8TGGTW53', transform_id='SmQmhrhigFPLz8', run_id='MAsFiWynt6ZzShK6Xhp5', initial_version_id='UYxBk5c2glqsNytkYhWE', created_by_id='DzTjkKse')
dataset_v2.save()
dataset_v2.labels.add(efs.fluorescence_activated_cell_sorting, features.assay)
dataset_v2.labels.add(species.human, features.species)
dataset_v2.view_flow()
